Повышение эффективности конкатенации списков за счет совершенствования структуры данных
До сих пор в наших программах конкатенация была определена так:
конк( [ ], L, L).
конк( [X | L1], L2, [X | L3] ) :-
конк( L1, L2, L3 ).
Эта процедура неэффективна, если первый список - длинный. Следующий пример объясняет, почему это так:
?- конк( [а, b, с], [d, e], L).
Этот вопрос порождает следующую последовательность целей:
конк( [а, b, с], [d, e], L)
конк( [b, с], [d, e], L') где L = [a | L']
конк( [с], [d, e], L") где L' = [b | L"]
конк( [ ], [d, e], L'") где L" = [c | L''']
true (истина) где L'" = [d, е]
Ясно, что программа фактически сканирует весь первый список, пока не обнаружит его конец.
А нельзя ли было бы проскочить весь первый список за один шаг и сразу подсоединить к нему второй список, вместо того, чтобы постепенно продвигаться вдоль него? Но для этого необходимо знать, где расположен конец списка, а следовательно, мы нуждаемся в другом его представлении.
Один из вариантов - представлять список парой списков. Например, список
[а, b, с]
можно представить следующими двумя списками:
L1 = [a, b, c, d, e]
L2 = [d, e]
Подобная пара списков, записанная для краткости как L1-L2, представляет собой "разность" между L1 и L2. Это представление работает только при том условии, что L2 - "конечный участок" списка L1. Заметим, что один и тот же список может быть представлен несколькими "разностными парами". Поэтому список [а, b, с] можно представить как
[а, b, с]-[ ]
или
[a, b, c, d, e]-[d, e]
или
[a, b, c, d, e | T]-[d, e | T]
или
[а, b, с | Т]-Т
где Т - произвольный список, и т.п. Пустой список представляется любой парой L-L.
Поскольку второй член пары указывает на конец списка, этот конец доступен сразу. Это можно использовать для эффективной реализации конкатенации. Метод показан на рис. 8.1. Соответствующее отношение конкатенации записывается на Прологе в виде факта
конкат( A1-Z1, Z1-Z2, A1-Z2).
Давайте используем конкат для конкатенации двух списков: списка [а, b, с], представленного парой [а, b, с | Т1]-Т1, и списка [d, e], представленного парой [d, e | Т2]-Т2 :
?- конкат( [а, b, с | Т1]-T1, [d, е | Т2]-Т2, L ).
Оказывается, что для выполнения конкатенации достаточно простого сопоставления этой цели с предложением конкат. Результат сопоставления:
T1 = [d, e | Т2]
L = [a, b, c, d, e | T2]-T2
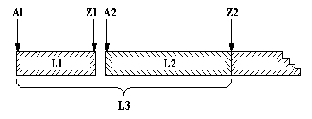
Рис. 8. 1. Конкатенация списков, представленных в виде разностных пар.
L1 представляется как A1-Z1, L2 как A2-Z2 и результат L3 - как A1-Z2.
При этом должно выполняться равенство Z1 = А2.